Faster builds - part 1
At LMAX Exchange we’ve been using Buck and a monolithic source tree for about 18 months. Prompted by the recent talk from Google on how they do this kind of thing at massive scale and some similar articles from Twitter I thought I should post on how we do these things at LMAX where we call our engineering effectiveness team “Technical Engineering”.
Life before Buck
In 2013 most development was taking place against a single large source tree with a handful of other source trees that got occasional updates. The main tree contained all the code, configuration and tests for our core exchange. The satellite modules (about 15) either depended on code in the exchange or were depended on by this code.
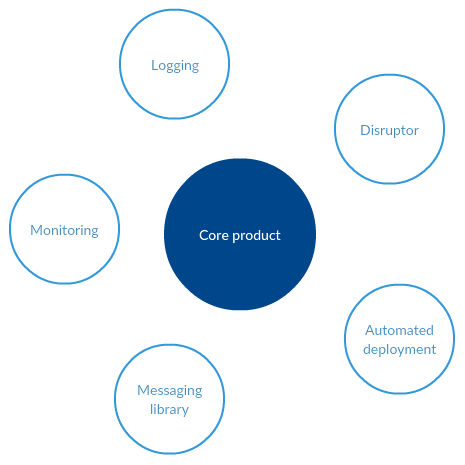
This is fairly standard coarse-grained modularisation of the code, mostly driven by either a technical separation of modules, a deployment lifecycle separation or in a few isolated cases, business concept separation. Each module was a separate Subversion project, i.e. each had the /trunk, /branches, /tags structure. So when you committed a change to “monitoring” that relied on a change to “exchange” then you would be making two separate commits, each with its own Subversion revision number. For a brief (and sometimes not so brief) period there would be code in one module that didn’t work with code in the other modules.
The build itself was based on Ant and there was some Ant script shared between the both the main and satellite modules. A typical build would first clean everything, then compile, package, test, analyse, etc. In order to integrate modules you would do this to each module, then commit which triggered a publish, then go back to the dependent modules and update version labels to point at the new published artifacts. This in turn would cause new version of the dependers to be built, necessitating updates to modules that depended on them, etc.
In short, keeping these modules in-sync wasn’t pleasant and often took a developer a whole day if the dependency being updated was deep within a tree. We had to develop tooling just to assist this task. Most concerning of all in terms of the long term direction of our build process - the more modular you got, the more painful this process got - a trendline pointing in the wrong direction.
Being Ant-based, most build targets were single-threaded meaning the high core count on our pairing stations and in our CI environment wasn’t helping. The exception being the unit tests which were run in parallel thanks to LMAX’s parallel-junit.
This kind of friction discourages devs from using modules at all and breeds a resentment for the tools and processes. We’ve all been here and many teams accept this as an acceptable price of modularisation - after-all, there’s so many tools in Java-land that support this approach as a de facto standard - Maven, Ivy, Artifactory, etc.
Looking at our build process, a few things seemed counter-intuitive.
- Modularisation is good for the long-term maintainability so why should introducing modules have such a negative impact on our build process?
- Why can’t I throw more cores at this build process to make it go faster?
- Why do my builds start from a clean-slate and rebuild the same code over and over again?
Enter Buck
As an experiment, I once tried to compile all our Java code from all the modules in one go, i.e. a single call to javac.
It took about 70 seconds to compile. This seemed really very significant.
Why? At that time our build process would compile, test and package the code for deployment in about 5 minutes but only if you’d already compiled and packaged all the other modules (a couple of minutes each) and setup the versions correctly (yuck, hours). Where was all that additional time going?
We started dropping BUCK files into our main module. There were some clear “seams” where modules were trying to emerge and we could materialise these easily with a judiciously placed BUCK file. It’s orthogonal to the theme of this post but it’s interesting that our code clustered into groups with clearly defined responsibilities (i.e. modules) but our build process was resisting bringing these modules out into the open.
Build times began to drop as the build steps began running concurrently. During this period we were supporting Ant and Buck builds concurrently which added a few challenges.
Once the main module was largely building with Buck we started moving the other modules under the same source tree and watched as manual module integration just didn’t need to happen anymore. The team were happier, modularisation stopped being a dirty word, dependency management for both 3rd party tools and internal modules became quick and easy.
A whole class of expensive activities just vanished from our process.
Taking a leaf out of the LMAX continuous performance tuning book we started measuring build times a few months before we began migrating to Buck (we now have data for half a million builds). We saw the number of builds per day increase while the total time spent building remained roughly the same. We now build about 5 times as often as we did 18 months ago. Most builds now take less than a minute and are proportional to the amount of change rather than the total size of the code. Developers crave feedback, if we can get feedback quicker then we just grab more.
I’ll reiterate this because I think it’s really important. The two principle questions that a developer should be asking about their commits:
- Does my code work?
- Did I break anything else?
It now takes less than a minute to get an answer.
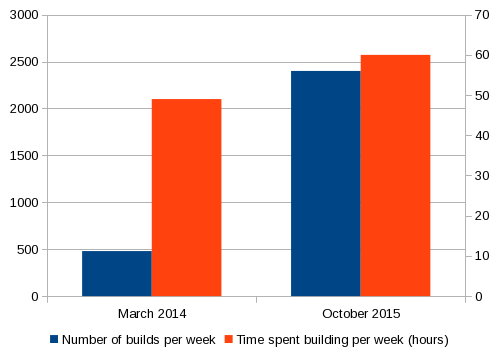
The mean build time is around 90 seconds due to a couple of long-running build targets, we’re working to eliminate these. The median falls way below the one minute mark.
Why is it faster?
Parallelism
Bearing in mind that our Ant build was largely single-threaded, our first win was parallelism.
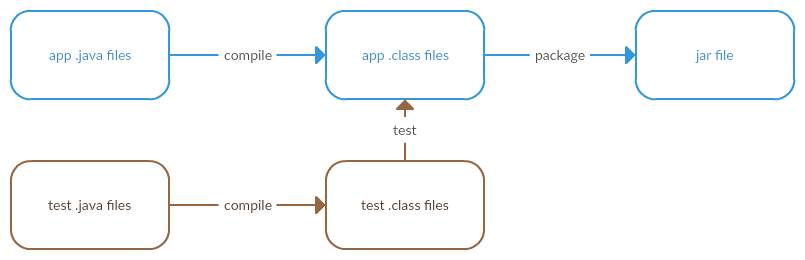
Take the basic anatomy of building a Java application.

Let’s add some testing.
And a little bit of static analysis.
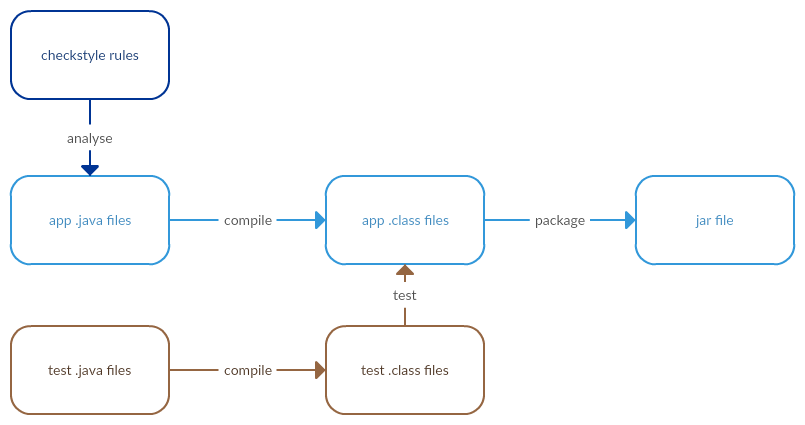
What does Buck do with this?
There are 5 verbs in this diagram - analyse, compile (x2), test and package. Buck calls these rules. Each rule can have inputs and an output. From these rules we can construct a directed acyclic graph of dependent rules such that a rule depends on another if it needs the outputs as its inputs.
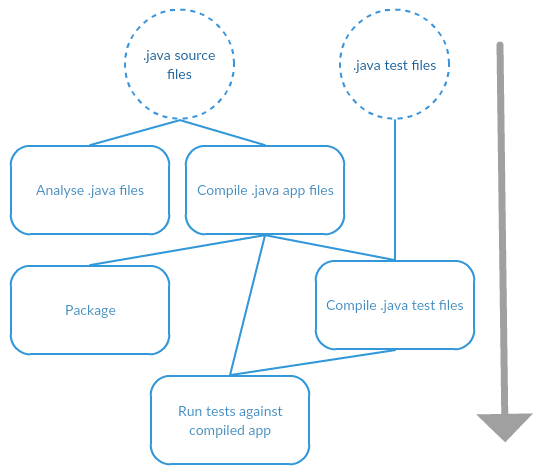
By laying out the rules in this way we can see that a degree of parallelism is possible during execution. i.e. you can analyse the java source while you’re compiling it. You can package it while you’re compiling its tests.
Note that this is an example of a single (simple) Java module, resulting in a single .jar file. I draw attention to this point because fans of Maven often write-off this feature of Buck because Maven also has a parallel mode but last time I looked this only applied to modules as a whole, not the individual activities within a module.
Now multiply this by the number of Java modules in your app, building a single DAG containing all the rules. Execute the DAG across multiple cores and you can expect to have all your cores at 100% utilisation for the majority of the build. Our build has several thousand parallelisable jobs so effective multi-core execution really makes a difference.
To be continued…
In the next installment we’ll cover some of the other reasons why building in this way is faster.